October 8, 2024
Llama 3.1 Swallow
Llama 3.1 Swallow is a series of large language models (8B, 70B) that enhance Japanese language capabilities while maintaining the English abilities of Llama 3.1. The model parameters (weights) are available on HuggingFace, allowing usage for research and commercial purposes as long as it complies with the Llama 3.1 license (uses of instruction-tuned models must comply with the Meta Llama 3.1 Community License and must not violate the Use Restriction set forth in the Gemma Terms of Use). Llama 3.1 Swallow is based on Meta Llama 3.1 and was developed by the research team at the Okazaki Laboratory and Yokota Laboratory of the Institute of Science Tokyo, and the National Institute of Advanced Industrial Science and Technology (AIST). Built with Llama.

Legacy (higher-performance models have been developed and released)
Models
ChangeLog
- 2024-12-30: Released Llama 3.1 Swallow 70B Instruct v0.3 and updated the website. This version was instruction-tuned using the same dataset as Llama 3.1 Swallow 8B Instruct v0.3, improving Japanese multi-turn dialogue capabilities. The difference between v0.1 and v0.3 lies solely in instruction tuning, as both share the same base model, Llama 3.1 Swallow 70B v0.1. (As a result, v0.2 and the base model’s v0.3 are skipped). This release is a minor update that integrates the Swallow team’s latest insights into model construction. There are no issues with version 0.1.
- 2024-12-23: Released Llama 3.1 Swallow 8B Instruct v0.3 and updated our website. In v0.3, instruction tuning was conducted using newly developed data, significantly improving Japanese multi-turn conversational capabilities. The average score on the Japanese MT-Bench improved by 8.4 points from v0.2 to v0.3, achieving a top-tier score of 0.6424 among models in this class. Furthermore, instruction-following capabilities in multi-turn conversations were enhanced. The only difference between v0.2 and v0.3 lies in the instruction tuning, as both share the same base model, Llama 3.1 Swallow 8B v0.2 (hence, there is no base model labeled as v0.3). This release is a minor update incorporating the latest insights from the Swallow team, and there are no issues with versions 0.1 or 0.2. Due to the termination of ABCI 2.0 operations at the end of October 2024, it has not been possible to develop new versions of Llama 3.1 Swallow 70B. If the opportunity arises, we plan to update the 70B model in the future.
- 2024-11-11: Released Llama 3.1 Swallow 8B v0.2 and Llama 3.1 Swallow 8B Instruct v0.2, and updated the website description. Changes in v0.2 include improvements in the quality of training data for Japanese program code, and a review of the Japanese-English data ratio. Additionally, Llama 3.1 Swallow 8B Instruct v0.2 continues pre-training from Llama 3.1 8B Instruct (whereas v0.1 continued from the base model) and includes further instruction tuning. This minor update incorporates our latest insights into model construction and does not indicate any issues with v0.1. Due to the termination of ABCI 2.0 operations at the end of October 2024, we were unable to complete v0.2 of the Llama 3.1 Swallow 70B model. We hope to update the 70B model at a later date if possible.
- 2024-10-08: Released Llama 3.1 Swallow.
License
The license for Llama 3.1 Swallow inherits from the Meta Llama 3.1 license. Additionally, for the use of the instruction-tuned models, Llama 3.1 Swallow 8B Instruct and Llama 3.1 Swallow 70B Instruct, users must not only comply with the Llama 3.1 License but also ensure that they do not violate the usage restrictions outlined in the Gemma Terms of Use. Provided the license and restrictions (applicable to the Instruct models only) are adhered to, research and commercial usage of these models are permitted.
Evaluation
The Swallow team is advancing research and development with the goal of creating large language models (LLMs) with strong Japanese language capabilities. This is to elucidate the mechanisms and methods behind constructing LLMs that exhibit high abilities of language understanding, generation, and coversation. In addition to evaluating prototype LLMs developed by the research team, we also conduct evaluation experiments on LLMs created by other companies and research institutions to explore the “recipe” for developing excellent LLMs. From April 2024 to October, we have conducted over 400 experiments.
The Swallow project aims to build general LLMs model that can be easily fine-tuned for specific applications when necessary, rather than improving performance on specific tasks. For the 2024 fiscal year, the Swallow project employs question-answering tasks to test common knowledge, language generation tasks such as automatic summarization and machine translation, exams, and tasks requiring logical reasoning such as math and code generation. These evaluations are conducted with 10 datasets for Japanese understanding and generation tasks, and 9 datasets for English understanding and generation tasks. Additionally, to measure Japanese conversational ability, we conduct evaluations using a Japanese MT-Bench with GPT-4 as the judge.
For all tasks, evaluation scores range from 0 (minimum) to 1 (maximum). Notably, our Japanese MT-Bench evaluation results are observed to be lower than those on external leaderboards, even when our scores are scaled up tenfold to a 10-point system. While many external leaderboards use GPT-4 (gpt-4-0613) as a judge, we use GPT-4 (gpt-4-1106-preview), which is thought to be the cause of the score differences. Our investigations revealed that although there is a notable discrepancy between our results and those of external leaderboards, the rankings of the models remain mostly unchanged. Therefore, due to the substantial number of completed evaluations, we have chosen to continue with the version of GPT-4.
For more details on the evaluation, please refer to the Japanese LLM Evaluation.
8B Base
Since the performance of LLMs tends to increase with the number of parameters, it is essential to compare models of similar scale to evaluate the effectiveness of a model’s design recipe. However, comparing models of different scales can help users make informed choices, so we compared the performance of Llama 3.1 Swallow 8B against LLMs with fewer than 13B parameters. Below is a graph showing the average scores for Japanese understanding and generation tasks, sorted in descending order for base models with 13B parameters or fewer.

The average score for Japanese understanding and generation tasks with Llama 3.1 Swallow 8B v0.2 is 0.4991, representing an increase of 2.74 points from the previous Llama 3 Swallow 8B version’s score of 0.4717, marking the highest score among open LLMs under 8B parameters. Additionally, Llama 3.1 8B achieved an average score of 0.4359, indicating a 6.32-point improvement in Japanese understanding and generation tasks through continual pre-training. Compared to Swallow 7B (released in December 2023), Swallow-MS 7B v0.1 (released in March 2024), and Llama 3 Swallow (released in July 2024), Llama 3.1 Swallow shows a steady increase in average scores.
When comparing the minor updates before and after (v0.1 and v0.2), JHumanEval improved by 5.49 points, and the question-answering task related to Japan (NIILC) rose by 2.61 points. We believe this improvement is due to our efforts in enhancing the quality of training data for Japanese and program code, and adjusting the Japanese-English data ratio. In addition, the average score for Japanese understanding and generation tasks increased by 0.86 points from 0.4905 of v0.1.
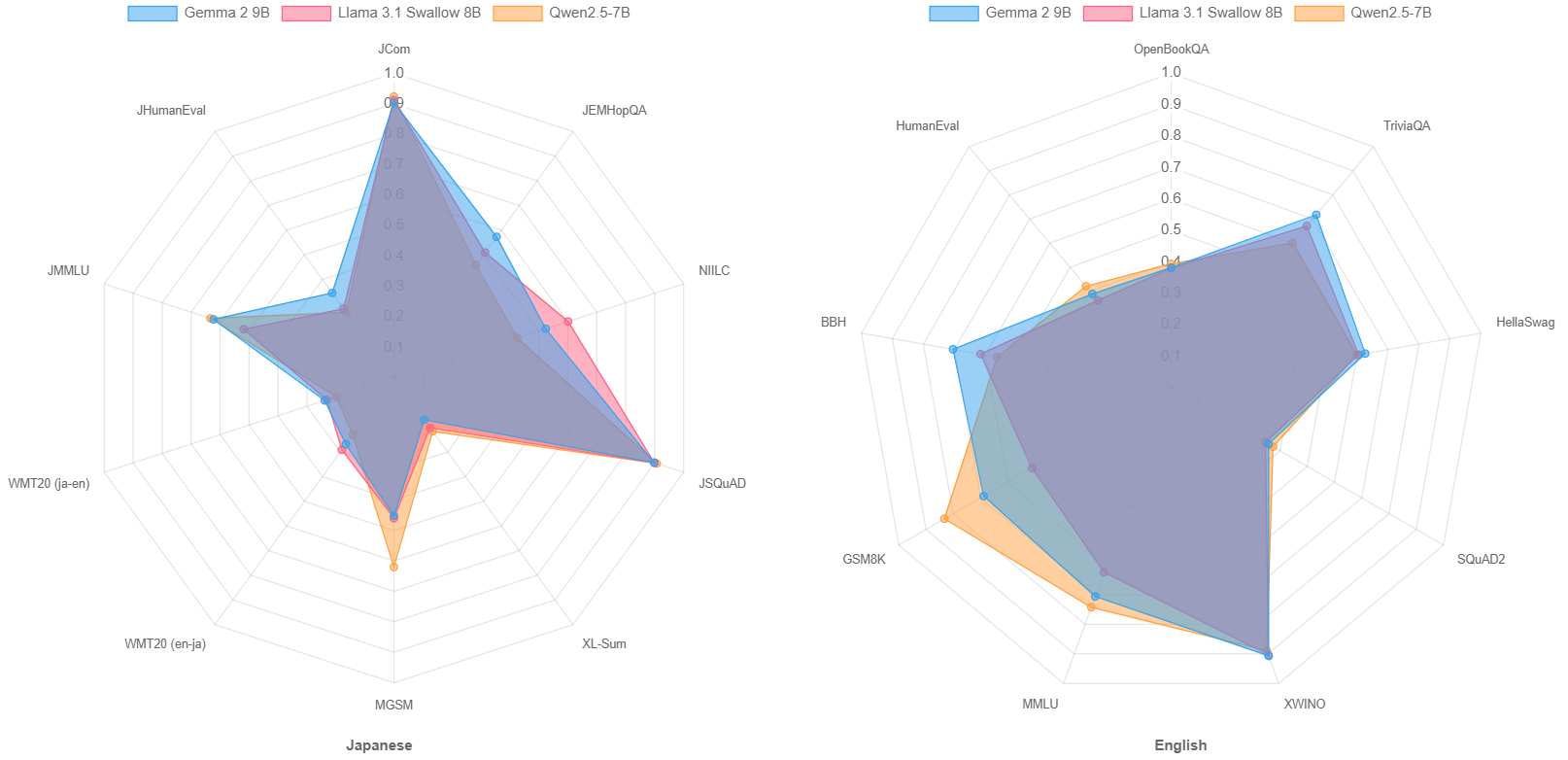
Looking beyond the Swallow models, Qwen2.5 7B and Gemma 2 9B also demonstrate impressive performance. These models are multilingual, making it notable that they perform well even without being specialized for Japanese. There is a nominal 1B parameter difference between Qwen2.5 7B and Llama 3.1 Swallow 8B, which highlights Qwen2.5 7B’s impressive capabilities. However, if we consider decimal precision, Qwen2.5 7B has 7.6B parameters, while Llama 3.1 Swallow 8B has 8.0B, meaning the actual size difference is only 0.4B, which may change this impression. Gemma 2 9B is the strongest among this class of models. At the same time, the difference of average scores between Llama 3.1 Swallow v0.2 and Gemma 2 9B is only 0.05 point, which indicates non distinguishable difference in performance. Since Gemma 2 9B has 9.2B parameters, Llama 3.1 Swallow 8B v0.2 competes well despite a 1.2B parameter disadvantage.
We visualized the scores of these three models on language understanding and generation tasks in Japanese and English using a radar chart. This chart reveals that Qwen2.5 excels in tasks involving mathematics (MGSM and GSM8K), general knowledge (JMMLU and MMLU), and code generation (JHumanEval and HumanEval), while Llama 3.1 Swallow is particularly strong in Japanese knowledge tasks (NIILC) and Japanese language generation tasks (WMT20 en-ja).
8B Instruct
Similarly, the graph below shows the average scores for Japanese understanding and generation tasks, Japanese MT-bench, and English understanding and generation tasks for major instruction-tuned models with 13B parameters or fewer. In this graph, the models are arranged by average scores on Japanese MT-bench scores.

The Japanese MT-Bench average score for Llama 3.1 Swallow 8B Instruct v0.3 is 0.6424, placing it among the top-performing Japanese LLMs with fewer than 13B parameters, second only to Gemma 2 9B IT, which scored 0.6753. This update marks the largest performance improvement (8.4 points) in the history of 8B Instruct models since Llama 3 Swallow, achieving a total improvement of 16.58 points compared to the Llama 3 Swallow 8B Instruct released approximately six months ago.
| Model | Japanese MT-Bench average score | Release date |
|---|---|---|
| Llama 3 Swallow 8B Instruct | 0.4766 | July 1, 2023 |
| Llama 3.1 Swallow 8B Instruct v0.1 | 0.5327 | October 8, 2024 |
| Llama 3.1 Swallow 8B Instruct v0.2 | 0.5584 | November 11, 2024 |
| Llama 3.1 Swallow 8B Instruct v0.3 | 0.6424 | December 23, 2024 |
Given these advancements, Llama 3.1 Swallow 8B Instruct v0.3 represents significant evolution as an instruction-tuned model, and we highly recommend utilizing this version for future applications.
70B Base
Next, we analyze the performance of the Llama 3.1 Swallow 70B base model. The graph below shows the major base models with 20B parameters or more, ranked by their average scores on Japanese understanding and generation tasks.

The average score for Japanese understanding and generation tasks with Llama 3.1 Swallow 70B is 0.5932, falling short of Qwen-2.5 72B’s score of 0.6232. Additionally, this score is nearly identical to the previous version, Llama 3 Swallow 70B, which scored 0.5934, suggesting that performance has not improved as much as we anticipated. One factor contributing to this outcome may be the emphasis on maintaining English capabilities during the continual pre-training.
The table below summarizes the average scores on Japanese and English understanding and generation tasks for Llama 3 and Llama 3 Swallow, as well as Llama 3.1 and Llama 3.1 Swallow, before and after continual pre-training. While the Llama 3 Swallow saw a decrease of 1.56 points in English understanding and generation scores, Llama 3.1 Swallow 70B experienced an increase of 1.46 points. This suggests that during the continual pre-training for Llama 3.1 Swallow 70B, the effort to maintain English performance may have led to a plateau in Japanese performance.
When constructing Llama 3.1 Swallow, we conducted validation experiments with the 8B model to find an optimal balance between Japanese and English performance and used this data to determine the composition of training data. However, as English performance actually increased in the 70B model, it may be necessary to adjust the corpus composition according to model scale (larger models like the 70B may be less prone to forgetting English). In any case, these results, which show an improvement in English performance, provide intriguing insights into how to build robust LLMs strong in both Japanese and English.
| Evaluation Task | Llama 3 70B | Llama 3 Swallow 70B | Llama 3.1 70B | Llama 3.1 Swallow 70B |
|---|---|---|---|---|
| Japanese understanding & Generation | 0.5682 | 0.5934 (+0.0252) | 0.5662 | 0.5932 (+0.0270) |
| English understanding & Generation | 0.6905 | 0.6749 (-0.0156) | 0.6748 | 0.6894 (+0.0146) |
Aside from Swallow, the standout models are Qwen2.5 72B and Gemma 2 27B. Despite being a multilingual model, Qwen2.5 72B achieved the highest score in this class with 0.6232. Although not shown in the graph above, the previous version, Qwen2 72B, scored 0.5937, showing steady improvement in version 2.5. Gemma 2 27B also performed remarkably well, surpassing larger models like the 35B and 47B Mixture-of-Expert (MoE) models and standing on par with models in the 70B class despite its smaller parameter number.
70B Instruct
Finally, we analyze the performance of the Llama 3.1 Swallow 70B Instruct. The graph below shows the average scores on Japanese understanding and generation tasks, Japanese MT-bench, and English understanding and generation tasks for major base models with 20B parameters or more. In this graph, the models are arranged by average scores on Japanese MT-bench tasks.

The Japanese MT-bench average score for Llama 3.1 Swallow 70B Instruct v0.3 was 0.7115, surpassing GPT-3.5 (gpt-3.5-turbo-0125), which scored 0.6661. Among the models evaluated this time, it ranked fourth, following GPT-4o (gpt-4o-2024-05-13) with 0.7791, Qwen2.5-72B-Instruct with 0.7594, and Llama 3 Youko 70B Instruct with 0.7222. Additionally, it showed a 5.68-point improvement compared to the previous version, Llama 3.1 Swallow 70B Instruct v0.1, which scored 0.6547. With the significant performance improvements of Japanese open LLMs, it may be time to incorporate human evaluations (Chatbot Arena: Chiang et al., 2024) or increase question difficulty (Arena-Hard: Li et al., 2024).
Method
Llama 3.1 Swallow is constructed following these steps:
- Llama 3.1 Swallow base model: Continual pre-training (Fujii et al., 2024) is conducted on the Llama 3.1 8B and 70B base models (without vocabulary expansion).
- Llama 3.1 Swallow instruction-tuned Model: Supervised fine-tuning (SFT) is applied to the Llama 3.1 Swallow base model.
Swallow Corpus Version 2
For the continual pre-training of Llama 3.1 Swallow, we created a Japanese web corpus (Swallow Corpus Version 2) by extracting and refining Japanese text from the entire archives of Common Crawl (94 snapshots collected between 2013 and 2023, roughly 254.7 billion pages). Swallow Corpus Version 2 involved downloading these 254.7 billion pages, extracting around 8.3 billion pages identified to be in Japanese (roughly 12 trillion Japanese characters). The proportion of Japanese web pages in the Common Crawl was about 3.2%. This dataset is approximately four times the size of Swallow Corpus Version 1 (Okazaki et al., 2024) used for training Llama 3 Swallow (as measured by the total number of web pages used in corpus construction).
In Swallow Corpus Version 2, the corpus construction process was modified to facilitate the selection of text data suitable for LLM training. Common Crawl often revisits the same website at different times and may include similar content across different sites due to minor edits or reposting. To prevent models from memorizing data, it is essential to avoid repeatedly training on the same text. Therefore, a deduplication process is applied to the pre-training corpus, removing redundant text. This involves identifying sets of similar pages among billions, requiring substantial processing time and memory. Deduplication is thus a major challenge in corpus construction for pre-training.
As the number of web pages increases, so do the time and memory needed for deduplication. Thus, it is common to first filter (remove low-quality pages and select high-quality pages) to reduce the number of pages before deduplication. However, this process requires deduplication to be redone each time the filtering criteria are adjusted. To allow flexibility in experimenting with filtering methods, Swallow Corpus Version 2 performs deduplication first. Although this increases the necessary time and memory for deduplication, the Swallow team completed deduplication across all Japanese pages over about a month. The resulting Japanese web corpus after deduplication comprises 1.9 billion pages (3.2 trillion characters).
Selection of Educationally Valuable Texts
In the previous version, Llama 3 Swallow, efforts were made to improve Japanese knowledge-related tasks such as question answering (NIILC) and machine translation (WMT20) by carefully blending the pre-training datasets. However, no significant improvement was observed on general knowledge tasks (JMMLU), which became a challenge for the Swallow project. Thus, inspired by recent research (FineWeb-Edu (Penedo et al., 2024), DataComp-LM (Li et al., 2024), Dolma 1.7 (Ai2, 2024)), Llama 3.1 Swallow adopted an approach of carefully selecting small amounts of “educational” text to enhance performance on general knowledge tasks.
Specifically, Japanese Wikipedia articles in academic fields like STEM and social sciences were considered examples of “educational” text. About 60,000 such documents were selected as positive examples to train a FastText classifier for educational text. This classifier achieved over 99% accuracy on the validation dataset, effectively identifying documents similar to academic Wikipedia articles with high precision. Additionally, since FastText classifiers run efficiently on CPUs, it is a lightweight classifier that scales to the size of Swallow Corpus Version 2.
With this classifier, quality filtering could be performed independently of the heuristic rules (such as the proportion of Hiragana characters) used in Swallow Corpus Version 1. The team verified the effectiveness of these heuristics, retaining only the appropriate ones and combining them with the classifier for quality filtering. This approach not only removed low-quality documents but also aimed to extract more “educational” documents.
Examples of Discontinual Rules
- Length of the longest sentence in the text (texts were removed if they contained sentences that were too long)
- Proportion of repeated n-grams (texts were removed if the proportion was high)
Examples of Rules Retained
- Average length of sentences in the text (texts were removed if the length was too high or too low)
- Proportion of Hiragana in the text (texts were removed if the proportion was too low)
To evaluate these efforts, ablation experiments were conducted before constructing Llama 3.1 Swallow. The results showed that the introduction of the classifier and adjustments to the heuristic rules improved performance on multiple Japanese tasks, including general knowledge (JMMLU) and translation (WMT20). Notably, combining heuristics with the classifier achieved the highest performance, demonstrating the effectiveness of extracting “educational” Japanese text.
However, arithmetic reasoning (MGSM) showed a negative impact. This issue was mitigated by adding a specific mathematical dataset (Cosmopedia) during the training of Llama 3.1 Swallow, so it is not expected to be a problem in the actual continual pre-training process.
| Experimental Pattern | JCom. | JEMHopQA | NIILC | JSQuAD | XLSum | MGSM | WMT-20 (en-ja) | WMT-20 (ja-en) | JMMLU | JHumanEval |
|---|---|---|---|---|---|---|---|---|---|---|
| Traditional Heuristics | 88.6 | 45.6 | 56.1 | 89.1 | 19.7 | 34.4 | 26.1 | 17.8 | 45.7 | 22.3 |
| Combination of Traditional Heuristics and Classifier | 88.5 | 53.4 | 59.5 | 89.2 | 19.7 | 27.2 | 28.0 | 18.5 | 46.4 | 23.1 |
| Combination of Adjusted Heuristics and Classifier | 89.1 | 55.3 | 60.7 | 89.5 | 20.9 | 28.4 | 29.7 | 22.6 | 48.4 | 24.1 |
Ablation Experiment Settings
- Continual pre-training on 50B tokens of Japanese corpus based on Llama 3 8B
- The Japanese corpus consisted of Japanese Wikipedia (1.69B tokens) and Swallow Corpus (48.31B tokens), with only the quality filtering settings for the Swallow Corpus modified
- In experiments using the classifier, only the top 10% of texts by classifier score were extracted from the Swallow Corpus after applying heuristic rules
During the construction of Llama 3.1 Swallow, improvements exceeding 8% on general knowledge (JMMLU) for the 8B model compared to Llama 3 Swallow confirmed the effectiveness of selecting educationally valuable texts.
Maintaining English Proficiency During Continual Pre-training
When enhancing the Japanese capabilities of an LLM through continual pre-training, a decline in the model’s original capabilities — primarily its English understanding and generation abilities — is often observed. For example, continual pre-training from Llama 2 7B to Swallow 7B resulted in a 6.1-point drop in the average score for English understanding and generation tasks, while the continual pre-training from Llama 2 70B to Swallow 70B saw a 2.7-point decrease. While it is essential to anticipate some loss in English proficiency when teaching Japanese to an LLM, maintaining these original abilities is desirable for tasks like arithmetic reasoning, general knowledge, and code generation, as these skills transfer well from English to Japanese.
In developing Llama 3.1 Swallow, we carefully selected training data to improve performance on general knowledge and code generation tasks. We decided to use datasets like DataComp-baseline, which showed effectiveness in general knowledge tasks, and The Stack v2, which demonstrated positive results in code generation tasks. Preliminary experiments also explored the optimal blend of these datasets. As a result, continual pre-training from Llama 3.1 8B to Llama 3.1 Swallow 8B led to only a 0.6-point decrease in the average English understanding and generation score, while training from Llama 3.1 70B to Llama 3.1 Swallow 70B even resulted in a 1.4-point improvement.
The radar chart below illustrates the scores on English understanding and generation tasks before and after continual pre-training for Swallow 7B and Llama 3.1 Swallow 8B. While Swallow 7B shows noticeable declines across tasks, Llama 3.1 Swallow 8B demonstrates minimal score reduction. Insights into dataset selection and composition like this are vital for exploring methods to build LLMs strong in both Japanese and English.

The corpora used for continual pre-training are as follows:
- Cosmopedia
- Dclm-baseline-1.0 (Li et al., 2024)
- English Wikipedia
- Japanese Wikipedia
- Laboro ParaCorpus
- Swallow Corpus Version 2
- The Stack v2 (Lozhkov et al., 2024)
Enhancing Conversational Ability with Synthetic Data
Improving LLM’s conversational ability hinges on instruction tuning with diverse and complex prompts, as well as useful and fluent responses. Ideally, it would involve collecting real-world user prompts and manually providing suitable responses, but this process is extremely time-consuming and labor-intensive. To build training data more quickly and affordably, the research team opted to imitate responses from existing high-performance LLMs. Specifically, prompts from the LMSYS-Chat-1M dataset, which contains human-computer interaction data, were translated into Japanese. Then, responses were automatically generated using an open LLM with top-tier conversational ability. Following the methodology used in Llama 3.1 construction, multiple responses were generated, and the best response was selected through automatic scoring by an LLM. Additionally, quality was improved by identifying and removing duplicate prompts, template-based prompts, and unnecessary repetitive responses.
The datasets used for instruction tuning are as follows:
Instruction Tuning Data for Llama 3.1 Swallow Instruct v0.3
Japanese instruction tuning data covers following datasets.
lmsys-chat-1m-synth-ja-gemma2-2turns-wo-pii-and-template-instructions: A Japanese multi-turn instruction-response dataset synthesized from lmsys-chat-1m (Zhang et al., 2024). The first-turn human prompts were translated into Japanese using DeepL (machine translation), and responses to the translated prompts were generated with gemma-2-27b-it. Afterward, rejection sampling (n=6) was performed using gemma-2-27b-it for automated scoring. Second-turn user instructions and responses were synthesized using gemma-2-27b-it. The quality of the second-turn responses was scored by gemma-2-27b-it on a scale of of 1-10. Second-turn responses with scores lower than 9 were rejected, along with their corresponding instructions. Dialogues containing personally identifiable information (PII), template-based prompts, and duplicate prompts were removed.filtered-magpie-ultra-ja: The Japanese version of thefiltered-magpie-ultra-endataset, translated into Japanese using gemma-2-27b-it.gemma-magpie-greater-than-7: A Japanese question-answering dataset synthesized from scratch using gemma-2-27b-it. Prompts were generated with topic-specific prompts, and assistant responses were generated for these prompts. Filtering was then applied based on heuristic rules for quality and length. Then, gemma-2-27b-it was applied to score the quality of each of the reponse with a range of 1-10. Responses with scores lower or equal to 7, along with its corresponding instructions, were rejected.
English data are excluded during the instruction tuning of Llama-3.1-Swallow-Instruct-v0.3.
Instruction Tuning Data for Llama 3.1 Swallow Instruct v0.1 and v0.2
Japanese instruction tuning data covers following datasets.
lmsys-chat-1m-synth-ja-wo-pii-and-template-instructions: A Japanese single-turn instruction-response dataset synthesized from lmsys-chat-1m (Zhang et al., 2024). The first-turn human prompts were translated into Japanese using DeepL (machine translation), and responses to the translated prompts were generated with Llama-3.1-405B-Instruct. Afterward, rejection sampling (n=6) was performed using Llama-3.1-70B-Instruct for automated scoring. Dialogues containing personally identifiable information (PII), template-based prompts, and duplicate prompts were removed.filtered-magpie-ultra-ja: The Japanese version of thefiltered-magpie-ultra-endataset, translated into Japanese using gemma-2-27b-it.gemma-magpie: A Japanese question-answer dataset synthesized from scratch using gemma-2-27b-it. Prompts were generated with topic-specific prompts, and assistant responses were generated for these prompts. Filtering was then applied based on heuristic rules for quality and length.
English instruction tuning data covers following datasets.
lmsys-chat-1m-synth-en-wo-pii-and-template-instructions: Responses to the original English prompts from lmsys-chat-1m were generated following the same method used for the Japanese dataset,lmsys-chat-1m-synth-ja-wo-pii-and-template-instructions. Unlike the Japanese version, rejection sampling was omitted.filtered-magpie-ultra-en: A subset of the MAGPIE instruction tuning data, created by Llama-3.1-405B-Instruct, following the MAGPIE methodology (Xu et al., 2024) magpie-ultra. Specifically, only examples rated above average were selected.
Improving Processing Speed in Distributed Parallel Training
In training LLMs, distributed parallel training using multiple GPUs is essential. Increasing the number of GPUs improves overall processing speed, but communication between GPUs can become a bottleneck, leading to decreased processing speed (computational efficiency) per GPU. To mitigate this, we introduced a method to finely interweave computation and communication, helping to maintain computational efficiency. Additionally, we revisited the distributed parallel training configurations to find the optimal settings for training Llama 3.1 Swallow. Below shows the processing speed per GPU (TFLOP/s), or computational efficiency, during continual pre-training for Llama 3.1 Swallow. As shown in the graph, with a micro-batch size of 2, we confirmed that even when training the 8B model of Llama 3.1 Swallow on 128 GPUs (16 nodes) using A100 (40GB), computational efficiency (184.9 TFLOP/s) equal to or exceeding that of training on 8 GPUs (1 node) can be achieved.

Furthermore, increasing the number of GPUs occasionally led to unintended training interruptions, which negatively affected the training efficiency of LLMs. In the continual pre-training of Llama 3.1 Swallow, adjustments to communication settings significantly reduced such interruptions, enhancing the utilization efficiency of computational resources.
References
- Wei-Lin Chiang, Lianmin Zheng, Ying Sheng, Anastasios Nikolas Angelopoulos, Tianle Li, Dacheng Li, Banghua Zhu, Hao Zhang, Michael I. Jordan, Joseph E. Gonzalez and Ion Stoica. 2024. Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference. The Forty-first International Conference on Machine Learning (ICML), July 2024.
- Kazuki Fujii, Taishi Nakamura, Mengsay Loem, Hiroki Iida, Masanari Ohi, Kakeru Hattori, Hirai Shota, Sakae Mizuki, Rio Yokota, and Naoaki Okazaki. Continual Pre-Training for Cross-Lingual LLM Adaptation: Enhancing Japanese Language Capabilities. In Proceedings of the First Conference on Language Modeling (COLM), October 2024.
- Jeffrey Li, Alex Fang, Georgios Smyrnis, Maor Ivgi, Matt Jordan, Samir Yitzhak Gadre, Hritik Bansal, Etash Kumar Guha, Sedrick Keh, Kushal Arora, Saurabh Garg, Rui Xin, Niklas Muennighoff, Reinhard Heckel, Jean Mercat, Mayee Chen, Suchin Gururangan, Mitchell Wortsman, Alon Albalak, Yonatan Bitton, Marianna Nezhurina, Amro Abbas, Cheng-Yu Hsieh, Dhruba Ghosh, Josh Gardner, Maciej Kilian, Hanlin Zhang, Rulin Shao, Sarah M. Pratt, Sunny Sanyal, Gabriel Ilharco, Giannis Daras, Kalyani Marathe, Aaron Gokaslan, Jieyu Zhang, Khyathi Raghavi Chandu, Thao Nguyen, Igor Vasiljevic, Sham M. Kakade, Shuran Song, Sujay Sanghavi, Fartash Faghri, Sewoong Oh, Luke Zettlemoyer, Kyle Lo, Alaaeldin El-Nouby, Hadi Pouransari, Alexander Toshev, Stephanie Wang, Dirk Groeneveld, Luca Soldaini, Pang Wei Koh, Jenia Jitsev, Thomas Kollar, Alexandros G. Dimakis, Yair Carmon, Achal Dave, Ludwig Schmidt and Vaishaal Shankar. 2024. DataComp-LM: In search of the next generation of training sets for language models. arXiv:2406.11794.
- Tianle Li, Wei-Lin Chiang, Evan Frick, Lisa Dunlap, Tianhao Wu, Banghua Zhu, Joseph E. Gonzalez and Ion Stoica. 2024. From Crowdsourced Data to High-Quality Benchmarks: Arena-Hard and BenchBuilder Pipeline. arXiv:2406.11939.
- Naoaki Okazaki, Kakeru Hattori, Hirai Shota, Hiroki Iida, Masanari Ohi, Kazuki Fujii, Taishi Nakamura, Mengsay Loem, Rio Yokota, and Sakae Mizuki. Building a Large Japanese Web Corpus for Large Language Models. In Proceedings of the First Conference on Language Modeling (COLM), October 2024.
- Zhangchen Xu, Fengqing Jiang, Luyao Niu, Yuntian Deng, Radha Poovendran, Yejin Choi, Bill Yuchen Lin. 2024. Magpie: Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing. arXiv:2406.08464.
- Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Tianle Li, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zhuohan Li, Zi Lin, Eric Xing, Joseph E. Gonzalez, Ion Stoica and Hao Zhang. 2024. LMSYS-Chat-1M: A Large-Scale Real-World LLM Conversation Dataset. The Twelfth International Conference on Learning Representations (ICLR), May 2024.
Acknowledgemts
The research and development of the large language model Swallow has been supported by the AIST Project “Research and Development on Generative AI Foundation Models in the Physical Domain,” the “Core Integrated Technology Development for Next-Generation Artificial Intelligence and Robotics” project by the New Energy and Industrial Technology Development Organization (NEDO) (JPNP18002), specifically focusing on “Development of AI Application Technology for Decision Support in Design Risk Assessment Based on Expert Perspectives.” It is also supported by a project from the Ministry of Education, Culture, Sports, Science, and Technology (MEXT) aimed at “establishment of research and development centers to ensure the transparency and reliability of generative AI models”, along with other contributions. Additionally, data and insights developed by LLM-jp (LLM Study Group) were utilized for evaluating LLMs.